AI is now inevitable. So how to co-exist with it, and maybe use it in some sort of useful way. Warning – you’re gonna learn more about AI than you may want to – but it’s not that complicated.
I’m in charge of the boring parts of Jessica’s books. Assembling the text, covers, artwork, typesetting, and all that stuff that allows the book to be printed and sold. There have also been a small, expensive army of editors and other helpers in there, of varying value.
AI has improved pretty dramatically over the last couple of years, and I was wondering if I could use it to make life easier for me and maybe Jessica. So I created Jessica’s Crabby Editor. When you ask about its persona, it replies:
Maybe I could write an AI that would let Jessica chat with her book and the characters; not as a writing aid, but more so she could quickly re-situate herself when writing or editing different parts of the book. This in addition to identifying things like plot holes, continunity issues, and things unintentionally left unfinished which are largely mechanical but require close reading and attention to detail to find. Things I don’t want to do. Things a machine might be good at.
For those of you who are interested in this stuff there are already tools out there that do this.
Google Notebook LM is good https://notebooklm.google/

Marlowe AI looks good as well https://authors.ai/marlowe-pro/

These tools all work similarly; they ingest whatever text you give it into chunks, store it in a vector database, then when you ask a question if checks the local database for the answer, fetches a couple of chunks and sends it up to the AI to work out an answer. When you subscribe to a tool you don’t get to choose any of these parameters – you get what they give you. That’s fair.
So why not use those? Well, for one thing I write code and build things… so this is an opportunity for me to learn how to build something interesting since I learn by doing. Next, cost. They’re both about $20 a month which is fair if you use it all the time. Marlowe limits the number of reports you can get per month at 4 which seems a bit stingy. Specialized tools rarely get used all the time but they tend to be used a huge amount initially.
Plus they’re expensive compared to the underlying calls – even Crabby, which is programmed to use a ton of resources, costs about $0.05 a shot – so you’d need to ask 400 queries to spend the same amount – and if you don’t use it – it costs nothing. Costing nothing is good.
Next, I’m a huge fan of https://cursor.com/ – if you code anything it’ll speed you up 10x. Jessica got a new author page within an hour because of it https://jessi.ca.
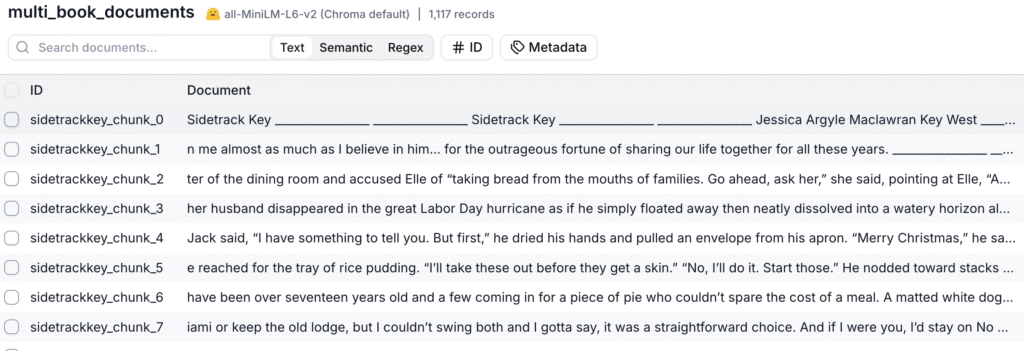
The vector database that stores the books is interesing. I’m using https://trychroma.com. AI with custom text depends upon RAG – Retrieval-Augmented Generation – so when you ask the AI something, it searches the stuff you uploaded first, extracts relevant context, and sends it along – that’s the Retreival Augmentation part. So Jessica’s books got chunked – that’s the correct term – into 950 character pieces and sent into Chroma.
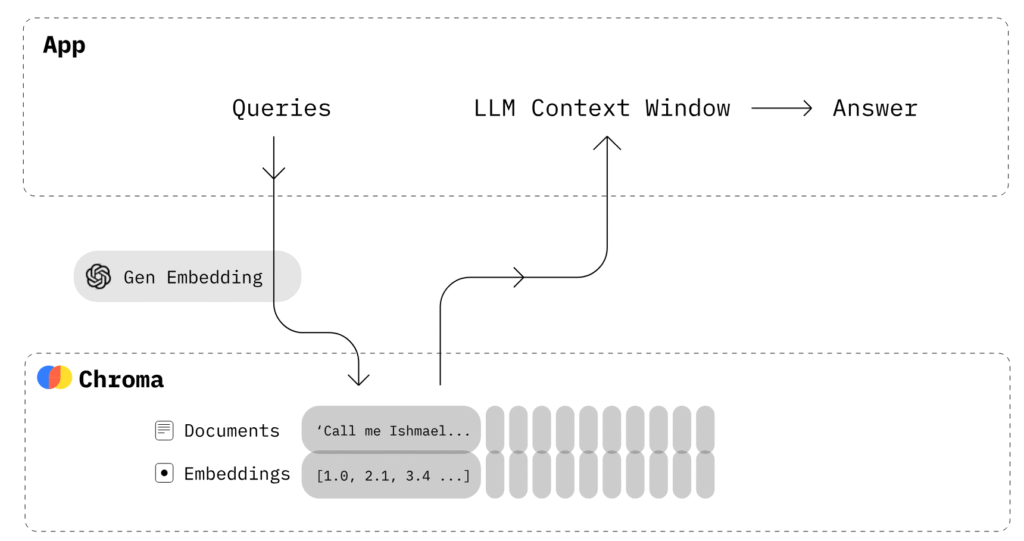
That vector DB, Chroma, then gets queried and it’s interesting because it doesn’t just look for words, it can grab things that are similar in meaning; a semanic search. My initial results were meh – I wasn’t providing the AI with enough context – in this case, relevant book parts, to be able to form a good answer.
So a search for “Does Elle love Brushy” would return all the most relevant chunks of the book where they’re involved and send all those chunks to the AI to help give it enough information to answer the question sensibly.
Right now every query is given 80 chunks (the most similar things out of that database) for about 80k characters of context; the context window in the graphic above – so chances are we’ll find what we’re looking for. It may even be too much, since it takes a while for the AI to come back with an answer.
The other improvement I made was to have it go through each book and summarize it, this is cached so we’ve always got as much context as possible to answer questions.
But that’s not all we send over. The last important bit is to tell the AI it’s persona. Telling the AI who they’re supposed to be gives it the correct context to answer your question in. If I told the AI that they were a Pediatrician with 20 years of experience, well, the context provided by what it knows about pediatrics wouldn’t that helpful here.
So, the persona is a Crabby Editor with 30 years of experience in editing Literary Fiction. In the code when asking for character analysis the prompt looks like this:
{“role”: “system”, “content”: “You are a literary analyst specializing in character analysis. Be thorough and insightful.”}
The more specific you can be, the more relevant your answers will be. I also specified a bunch of editing related tasks it should keep an eye out for. This part is going to need tweaking.
We’ve also got a token limit – how much each query can spend. Right now this is set to 2400; the temperature – how random the answers are is at 0.8 (this should be fun). If any of these parameters get any higher it’ll probably take the model too long to answer to be useful; these will all continue to get adjusted till we find the right balance.
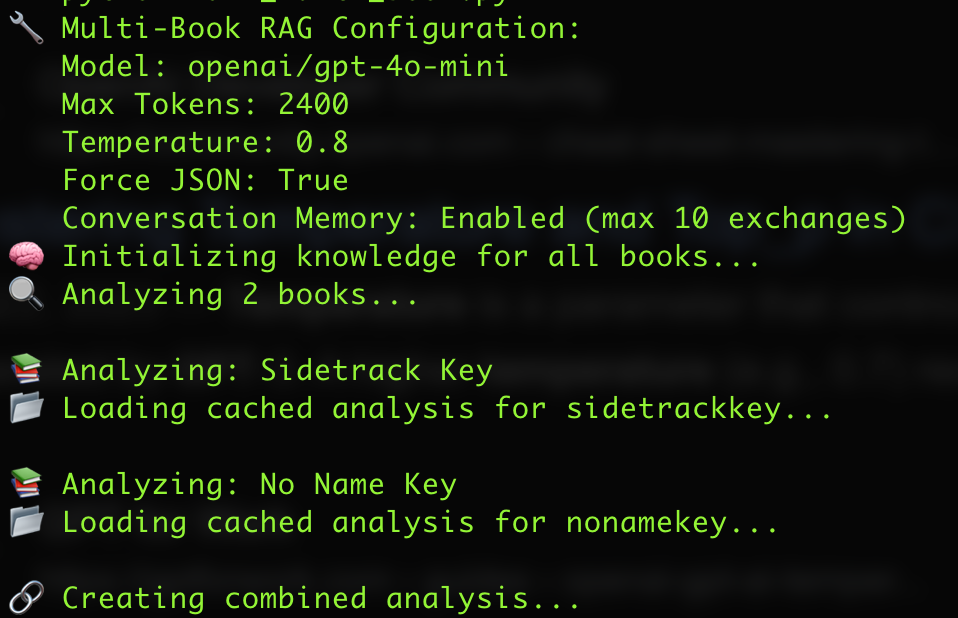
Right now we’re using gpt-4o-mini which is working fine. I suspect there’s going to be a lot of tweaking once Jessica embraces the machine.
If you want to try it go to https://ai.argyle.org – remember this is trained to specifically discuss Jessica’s books; you’ll be deeply frustrated if you want to learn more about how the Nazis lost World War 2.
If you want to see the code that made this, it’s available on Github.